
Kathryn Friedlander takes a look at an alternative way of studying expertise, the Grounded Expertise Components Approach, suggesting that this might address some pitfalls of previous research.
We’ve all seen the long-running arguments over ‘expertise’ … Are the world’s greatest performers endowed at birth with a lucky genetic advantage? Or are they trained to excel through 10,000 hours of gruelling practice? Or perhaps a blend of both?
The nature/nurture argument rages back and forth in the scientific and educational world, seemingly without resolution – but in my 2016 paper on cryptic crossword solvers, with Philip Fine, we argued that a number of methodological issues were getting in the way of a clear understanding. Here’s our take on the situation – and our suggestion for the way forward.
Issue 1: Do you really know your population?
Most studies of expertise usually start by looking at a specific population – whether that’s violinists, chess players or Scrabble players. It’s tempting to bring players into the lab to test them out on a variety of cognitive skills, using a battery of psychometric instruments – but how do we know which skills are most relevant?

Many studies begin by reviewing the psychological literature to see what other academics have said before – but there’s a risk of getting trapped in the same patterns of blinkered thought, and of research stagnation.
Here’s where a detailed knowledge of the population and the performance area is really helpful: without it we are just jumping into the deep end!
For example, earlier research on cryptic crossword solving (for reference, see footnote *) claimed that cryptic crossword experts were likely to possess ‘particularly rich lexical networks’ compared to non-puzzlers, leading to their success in this form of puzzle.
But when we conducted a wide ranging survey of cryptic crossword solvers of all standards, the most striking thing we found was that they were predominantly scientists, mathematicians and IT people (not arts, words and language people), and that this association increased with expertise. So solving a cryptic crossword may be more to do with code-cracking than with having an exceptional vocabulary. This would never have emerged so clearly from a simple reading of the literature.

Similarly, one of the main research papers on expertise in SCRABBLE assumed that expertise was vested in the possession of a wide vocabulary, strengthened by the deliberate learning of alphagrams over many years, and that there would be:
“relationships between scores on standardized tests that are frequently associated with verbal aptitude or verbal intelligence constructs (e.g., vocabulary or word fluency…) and skilled performance in the game of SCRABBLE.” (p.126)
Clearly, deliberate practice is important here: SCRABBLE players must memorize all 100k+ valid words of up to 8 letters in order to compete at the highest levels. So it’s not surprising that the expert SCRABBLE players trounced the other participants in the anagram-related tasks and other word-based challenges set by the researchers.
But is vocabulary and word fluency all they should have tested for? Not according to the players!
Jason Katz-Brown (#36 in the world in 2014): “Competitive Scrabble is a math game, and the level of strategy involved is one reason I keep playing.”
Paul Gallen (#7 in the world in 2014): “It is really a game of maths – you are just taking on extra work by trying to learn all the definitions [of the alphagrams].”
Mikki Nicholson (#23 in the world in 2014) ‘ “People think Scrabble is just about words but it’s the numbers that win the game, so a sound mathematical brain is an advantage,” she added.’

We can see that there’s a research trap here: alphagram learning through deliberate practice was almost bound to be correlated with performance on the limited set of word-based tasks in the trials, leading to the impression that deliberate practice alone was driving expertise. This chimed with the theoretical stance of the researchers, making it all the more likely that they would look no further for an explanation.
In fact, a wider survey of player opinion, and a greater knowledge of the game demands might have led the researchers to test a far wider range of skills. And this in turn could have led to a quite different interpretation: that deliberate practice might only have augmented a natural ability for (e.g.) strategy and the calculation of mathematical probability.
Issue 2: Observing experts engaged in ‘a representative task’
Another key approach in the expertise literature is to bring expert and non-expert performers into the lab, and to record them talking aloud while they carry out a task which is ‘fully representative of the performance domain’. Video recordings can then be transcribed and analyzed to see how experts differ in their execution of the task.
That’s all very well – but how do researchers select a ‘representative task’?
Traditionally, this conundrum was solved by turning to a paradigm set up by de Groot in early chess studies (for reference, see footnote **): the ‘Best Next Play’ test.

Participants in the trial are given a number of ‘preloaded’ boards, mimicking a series of unfinished games, and are ask to work out what their best next play would be in each situation, while talking aloud to show their reasoning.
Studies using this type of paradigm have found that experts do generally perform better than non-experts at this type of ‘one-shot’ challenge – whether we look at chess, SCRABBLE or cryptic crossword solvers.
So what’s the problem?
Well, the snag is that this type of challenge is only really testing the ability to come up with automatic, learned responses (the kind of thing experts train up on in the course of deliberate practice: chess opening gambits, SCRABBLE alphagrams etc). Experts with years of experience can reach into a kit-bag of solutions (‘chunked templates‘) memorized over a long time: the kind of problem-solving known as ‘System 1 thinking‘.
Because of this, the video recordings are also typically uninformative: a lean transcript with nothing but memorized candidate solutions, and no trace of any strategic self-talk. What would be the point, after all? The play is over at the end of that task, and there’s no need to consider any future implications, such as the opponent’s weaknesses, or the strategic endgame.
However, that means that there is precious little to analyze if we want to find out the differences in play execution between experts and non-experts.
In fact, there’s so much more to mind games such as SCRABBLE than simply coming up with a high-scoring play on each move. Jason Katz-Brown summarises the challenges of SCRABBLE this way:
“When playing top-notch opponents like Cappelletto or Sujjayakorn, I assume that they, like me, have memorized all 83,667 valid words of up to eight letters. Even then, the game requires the foresight of chess and the inferential strategy of poker. I must both maximize my score on the current turn and keep strong letters on my rack to increase the probability that I can maximize my score on future turns. I further aim to squelch opponents’ opportunities by guessing, based on their previous plays, which tiles they are most likely to be holding. By tracking tiles as they are played, I can also deduce exactly which tiles my opponent has in the endgame and plan my final plays accordingly.”
This type of ‘System 2’ thinking is untapped by the ‘Best Next Move’ paradigm, and we believe that this could have led to a systematic underplaying of the importance of creative and strategic play (while overstating the importance of rapid, automatic, memorized play laid down by practice routines).
What’s to be done about it all? The GECA Approach
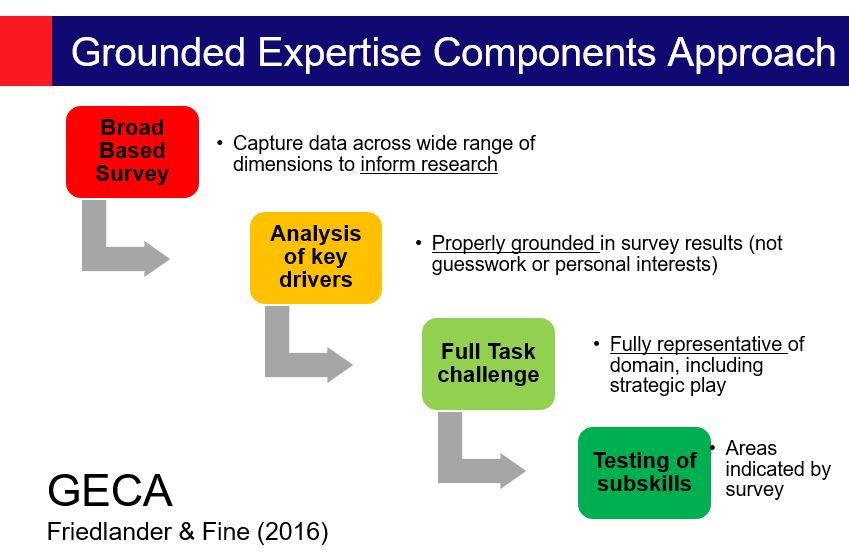
In our paper we suggested that expertise research needs to take a much more informed and grounded approach to studying expert populations.
First, we suggest that, although it is always essential to carry out a paper review of a domain, over-reliance on such an approach can lead to research stagnation, and unintended researcher bias. A secure empirical research rationale can only be provided by getting to know the population well – ideally by conducting a wide-ranging survey. This allows the research to highlight the key drivers of expertise, including unexpected or counter-intuitive findings.
Next, the ‘representative task’ selected for analysis should reflect the full challenge of the performance domain, including long-term strategic play and creative play-making. This will enable the transcription to yield data on all facets of expert play. In our cryptic crossword study, for example, we set our participants the challenge of solving a full, professionally commissioned crossword in 45 minutes, while we recorded them. This enabled us to look at aspects such as:
“…chosen solving order of clues; length of time spent in impasse on each clue before moving onto another; frequency of return to an obstinately resistant item; perseveration with an incorrect solution pathway; the antecedents of “Aha!” solution moments; and the use of cross-checking letters as solution prompts. The approach also permitted data capture on the clarity of understanding of clue architecture, frequency of dictionary use, handwritten jottings (such as candidate anagram letters) and the shifting emotional state of our participants (e.g., frustration, triumph, laughter).” (p.18)
Finally, researchers could test other sub-skills of interest, as indicated by the broad-based survey, such as intelligence, creativity, vocabulary or problem-solving ability. The important point is that these psychometric tests would be grounded properly in the survey findings.
In today’s rushed ‘publish or perish’ environment, it’s certainly a major investment to do your ground-work properly by surveying a population across a wide number of dimensions; but we believe the dangers of not doing so may be greater. GECA is a powerful methodology which updates and improves the original ‘Expert-Performance Approach‘ of Ericsson. It has already demonstrated useful findings which challenge the dominance of the 10,000 hour orthodoxy, and could be used in a wide range of expertise domains.
This blog is based on a presentation by Kathryn Friedlander at the BPS Cognitive Conference 2018, at Liverpool Hope, 29 – 31st August 2018, as part of the symposium ‘The Breadth of Expertise Research’, chaired by Dr Philip Fine.
*Underwood G., MacKeith J., Everatt J. (1988). Individual differences in reading skill and lexical memory: the case of the crossword puzzle expert, in Practical Aspects of Memory: Current Research and Issues, Vol. 2: Clinical and Educational Implications, eds Gruneberg M. M., Morris P. E., Sykes R. N., editors. (Chichester: Wiley; ), 301–308.
** de Groot, AD (1978). Thought and Choice in Chess (2nd. Edn.). New York, NY: Mounton De Gruyter
Image credits (all labelled free for reuse):
- Jumping in the deep end: https://www.flickr.com/photos/ornellas/8869268939
- Glasses on a crossword: https://cafesenior.pl/krzyzowka-swietny-sposob-na-nude-i-pamiec/
- De Groot paradigm: https://en.chessbase.com/post/the-geometry-of-expertise

Pingback: Calling all keen quizzers! | CREATE Ψ
Pingback: Cracking Psychology: Understanding the appeal of cryptic crosswords #1 – Puns and misdirection | CREATE Ψ
Pingback: Cracking Psychology: Understanding the appeal of cryptic crosswords #2 – Rebus-type clues (‘Say what you see’) | CREATE Ψ
Pingback: Cracking Psychology: Understanding the appeal of cryptic crosswords #3 – Anagrams | CREATE Ψ